

Environnement pour le catalogage d’ouvrages (manuscrits, imprimés anciens, imprimés modernes) en XML-EAD.
Le pôle Document numérique élabore des outils adaptés aux différents projets auxquels il contribue : environnements de travail en XML (EAD et TEI), feuilles de transformation, outils de travail collaboratif, moteurs d’affichage, etc.
Le pôle Document numérique (PDN) est un pôle pluridisciplinaire et une plateforme d’ingénierie de la Maison de la Recherche en Sciences Humaines (CNRS/Université de Caen Normandie).
Le PDN conçoit, développe et met en œuvre des outils numériques et des méthodes de travail pour les programmes de recherche en humanités et sciences humaines et sociales (SHS) avec une approche centrée sur les données. Cette orientation permet de concentrer les efforts de veille et de recherche sur les modèles de données plutôt que sur les outils d’exploitation. L’expertise développée sur ces modèles facilite la production de solutions génériques pour la manipulation, l’observation et la consultation des documents. Ces outils génériques sont ensuite adaptés à des problématiques scientifiques spécifiques.
Conçu comme source écrite, le document numérique est un ensemble de données variées qui peuvent être considérées et exploitées dans des configurations à géométrie variable. Ainsi, un témoin utilisé dans une édition de texte pourra être considéré comme un élément d’une base de données ou une notice descriptive (fonds, catalogue thématique…) dans un catalogue virtuel, etc.
Un des enjeux est ainsi d’assurer la mise en place d’un continuum numérique commun à l’ensemble des actrices et acteurs d’un projet afin de faciliter la possibilité du dialogue scientifique et/ou patrimonial autour de ces données. Il s’agit notamment de :
- disposer d’informations exploitables et récupérables ;
- produire de nouvelles informations à leur tour exploitables et récupérables ;
- préserver la qualité éditoriale (pour tous les supports) ;
- améliorer l’indexation des documents (permettre des recherches avancées) ;
- automatiser la production des formes diffusées et des bases de connaissances ;
- assurer l’archivage à long terme ;
- respecter les normes internationales (interopérabilité et circulation des données et des outils) ;
- articuler la valorisation du patrimoine et la recherche scientifique ;
- valoriser les fonds traités.
Des problématiques propres à ces champs d’ingénierie et de recherche déterminent les orientations de travail du PDN parmi lesquelles :
- l’analyse, l’édition, la diffusion de données/sources ;
- la tension croissante entre masse documentaire mise à disposition et outils d’appropriation, d’exploitation ;
- la diversification sensible du lectorat potentiel ;
- frontières poreuses entre conservation, communication, diffusion, valorisation, édition, analyse… ;
- document numérique comme outil et comme objet d’étude.
La notion de document numérique comme outil pour les chercheuses et chercheurs en humanités et en sciences sociales et comme objet d’étude à part entière alimente des réflexions plus générales et des travaux du PDN.
La démarche générale du PDN peut être présentée comme indiqué sur la figure suivante :
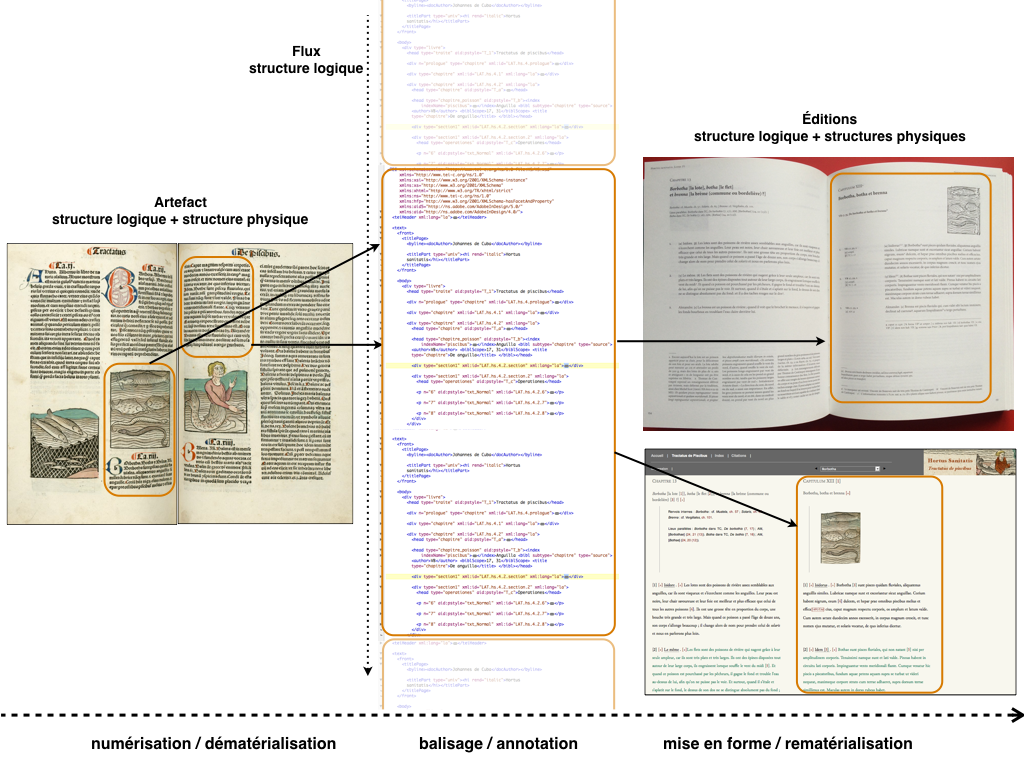
Le PDN accompagne les chercheuses et chercheurs en humanités et en sciences sociales dans la structuration, l’exploitation scientifique et la diffusion de leurs données textuelles.
Prescripteur de méthodes et d’outils innovants dans le champ des humanités numériques, il inscrit son action dans différents réseaux qui animent des projets ou programmes de recherche au plan local ou national (plateforme du RNMSH SCRIPTO, Réseau de compétences Humanités numériques et Information scientifique et technique, Équipex Biblissima + , consortiums de la TGIR Huma-Num (CAHIER, MASA)).
Dans le cadre de ces projets ou de conventions de collaboration, le PDN travaille avec de nombreux partenaires tels que : le CRAHAM, le LASLAR, le GREYC, le CITERES, l’IRHT, le CESR, l’IMEC, la BnF, la Bibliothèque Mazarine, Bayeux Museum, l’Institut européen des jardins et paysages.
L’analyse des exigences numériques de chaque projet permet d’identifier des besoins scientifiques, ou disciplinaires, spécifiques correspondant à des problématiques génériques (identification de sources, annotation de textes, mises en relation de parties de textes, reconstitution d’une transmission, recherche contextuelle, etc.). Le cas échéant, le PDN développe, le plus souvent en collaboration avec le CERTIC, un module adapté au problème générique qui est ensuite adapté au besoin précis et disciplinaire initial. Cette logique de factorisation permet de constituer, par cumulation, une bibliothèque d’outils réutilisables et réplicables.
L’apport du PDN aux projets dont il est partenaire réside principalement dans les méthodes d’établissement des objets numériques, les outils d’observation de ces objets et les solutions de diffusion. L’ensemble de ces méthodes s’appuie sur l’analyse du document numérique en tant qu’objet d’étude.
Projets et réalisations
Outils
Le pôle Document numérique élabore des outils adaptés aux différents projets auxquels il contribue : environnements de travail en XML (EAD et TEI), feuilles de transformation, outils de travail collaboratif, moteur d’affichage, etc.
nb : ces outils ont été construits dans des contextes spécifiques, vous pouvez les modifier, sous réserve de reproduire la licence Cecill, pour qu’ils répondent au plus près à vos besoins.
Plusieurs environnements de travail ont été conçus au sein du pôle Document numérique pour travailler avec l’éditeur XML, XMLMind XML Editor.
…en XML-EAD
Pour rédiger des instruments de recherche ou des catalogues, pour décrire les fonds de bibliothèques, pour créer des inventaires et des bibliothèques virtuels, nous mobilisons le vocabulaire XML-EAD, Encoded Archival Description . Nous utilisons la version EAD 2002, sous forme de schéma.

Environnement IEJP
Environnement pour la création d’instruments de recherche thématiques, notamment d’archives et d’inventaires, en XML-EAD.

Environnement Nummus
Environnement pour la description d’objets (notamment numismatiques) en XML-EAD.
… en XML-TEI
Dans le cadre de plusieurs projets, nous avons développé des environnements pour encoder les données textuelles en XML-TEI. La Text Encoding Initiative propose un ensemble de recommandations pour encoder les données textuelles en XML. Sauf mention contraire, les schémas que nous proposons au sein de ces environnements sont construits pour des projets très spécifiques : nous n’utilisons donc pas l’ensemble des balises proposées par la TEI, mais sélectionnons les éléments et les attributs utiles pour la description des objets textuels dans le cadre de chaque projet de recherche.

Éditer des inventaires anciens
Environnement d’édition scientifique d’inventaires anciens en XML-TEI compatible pour la publication de sources dans la collection Thecae.

Éditer des sources diplomatiques
Dans le cadre du projet e-Cartae, le pôle Document numérique a participé avec Grégory Combalbert à un travail de réflexion sur l’encodage en XML de chartes d’évêques. Il a ensuite…

Éditer des compilations médiévales
Dans le cadre du programme Ichtya (B. Gauvin et T. Buquet dir.), le pôle Document numérique a participé à une réflexion sur l’encodage en XML-TEI de compilations médiévales. Il a…

Éditer des sources anciennes
Environnement de travail pour l’édition de sources anciennes en XML-TEI proposé lors de l’atelier relatif à l’édition critique à l’occasion de l’école d’été Biblissima (Avranches 2016).
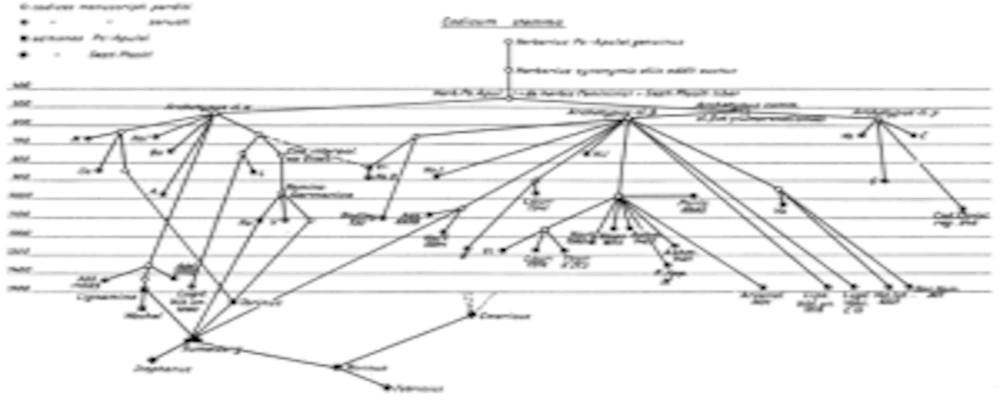
Éditer des sources avec apparat critique
Dans le cadre du projet d’édition critique de l’Histoire du Grand Comte Roger et de son frère Robert Guiscard de Geoffroi Malaterra, le pôle Document numérique a participé avec Marie-Agnès Lucas-Avenel…

Environnement Métopes
Cet environnement est un développement de l’Infrastructure de recherche Métopes, porté par le pôle Document numérique de la MRSH de Caen, en collaboration avec le CERTIC (Université de Caen Normandie). Un ensemble d’outils et…

Éditer des notices de thesauri
Dans le cadre de l’ÉquipEx Biblissima et en partenariat avec le Centre Michel de Boüard, le pôle Document numérique a participé à un travail de réflexion sur l’encodage en XML…

PluCo
PluCo est un plugin collaboratif permettant le travail d’édition collaboratif sur des ressources XML distantes développé en Java.
MaX
L’ensemble de nos projets en XML-TEI est mis en ligne grâce à un moteur d’affichage réalisé à l’université de Caen Normandie. La version la plus aboutie, MaX, est librement disponible…
Contact
Pôle Document numérique
Maison de la Recherche en Sciences Humaines
Université de Caen Normandie
Esplanade de la Paix – 14032 Caen Cedex
Collaborateurs et partenaires
Manifestations
Pas d'événement à venir